MLIR Dialect Usage Estimates
This page estimates the usage of MLIR dialects as lowering targets for the following repositories:
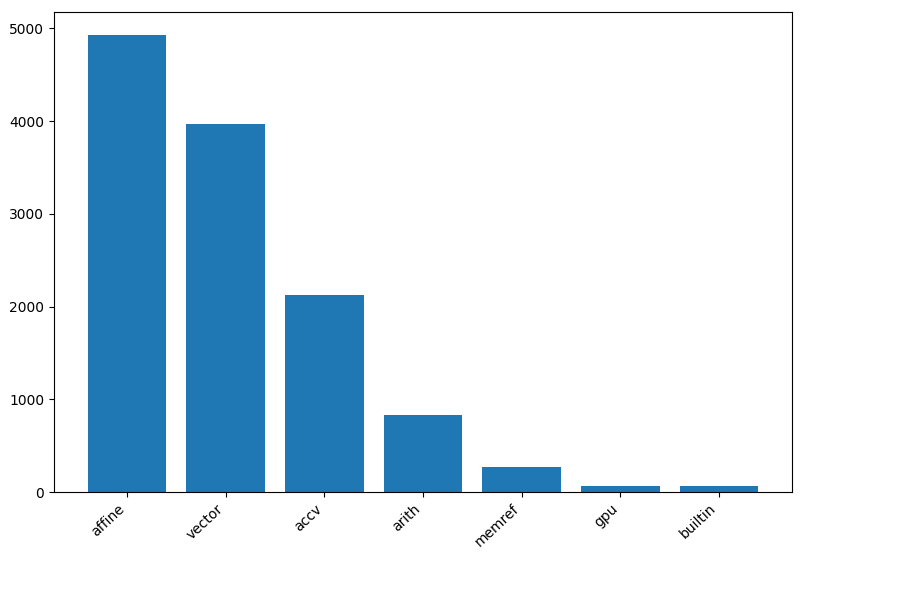
Usage is estimated by counting the number of matches after // CHECK: for each dialect operation in the repository tests.
This is based on the assumption that each compiler project lowers to various dialects, that a more important dialect is mentioned more often in test files, and that the downstream repositories use FileCheck.
Specifically, the following ripgrep rg command is used:
rg regex -g "*.mlir" repo_dirwhere
regex is the following regular expression:
[ ]*//[ ]*[^:]+: [ ]*[^%]*%[\[\]\.\+:a-zA-Z0-9_]+ = "?[^.]*\.which, for example, matches the following lines:
// CHECK: %0 = arith.constant 1 : index
// FULL-UNROLL: %cst = arith.constant 1 : index
// CHECK: %[[VAR:.+]] = arith.constant 1 : index
The source code for this page is available at https://github.com/rikhuijzer/mlir-dialects.
mlir
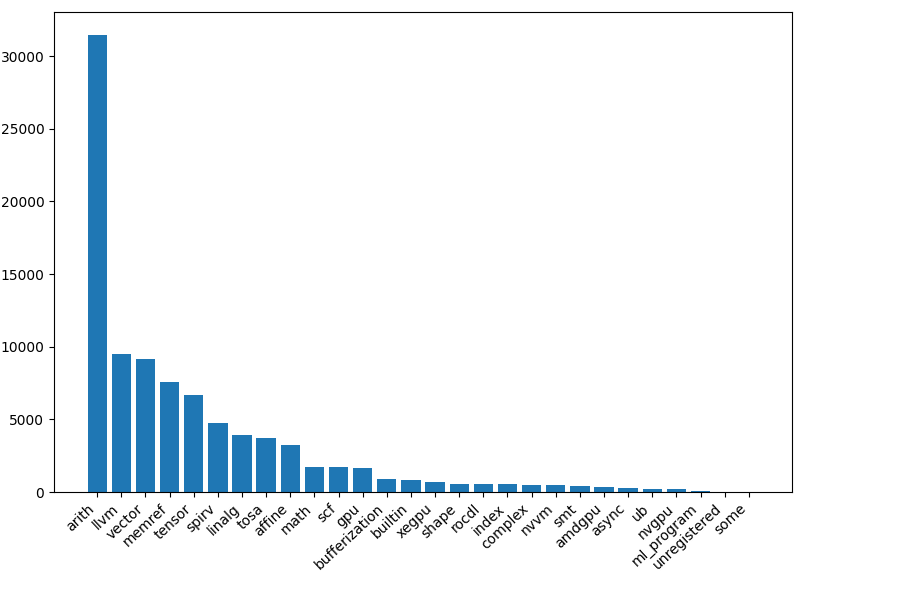
iree
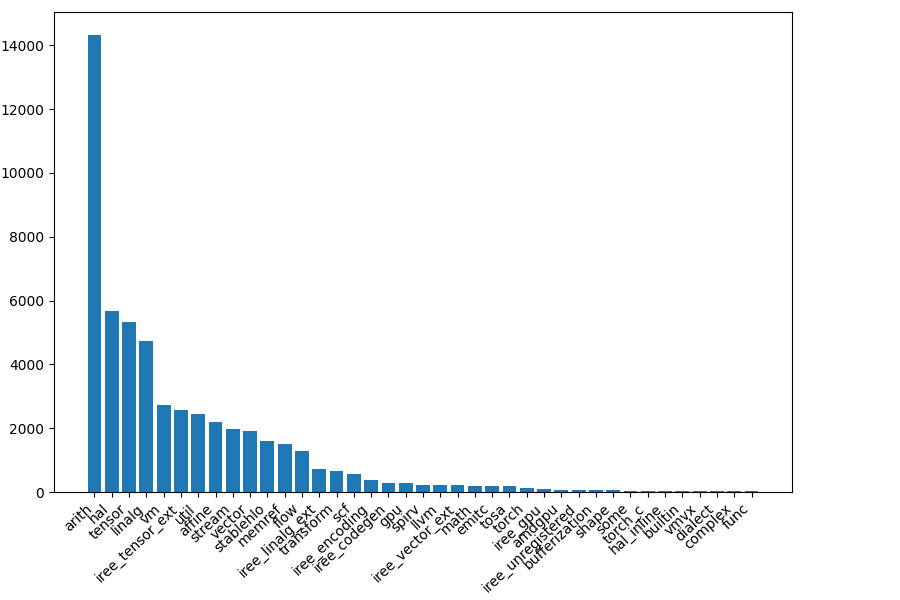
tensorflow
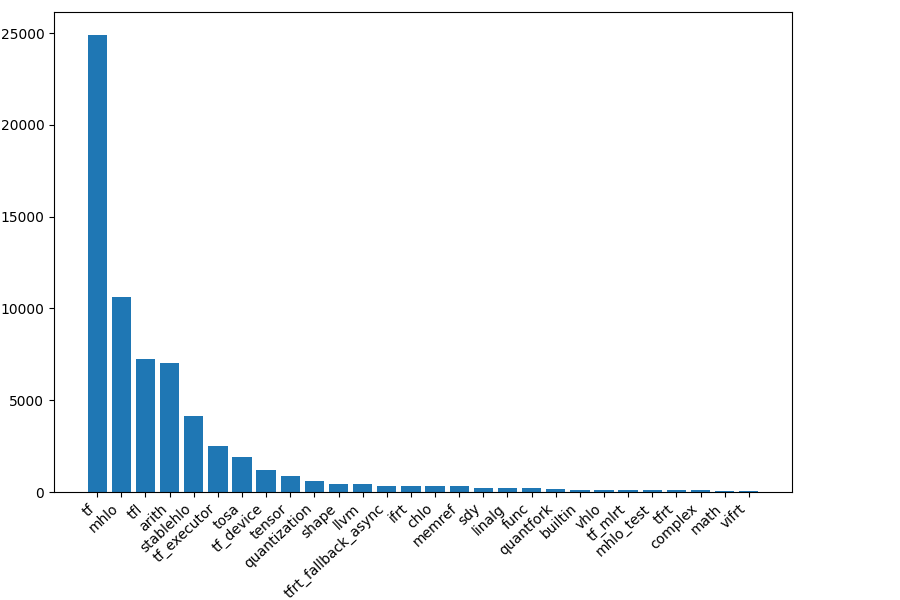
xla
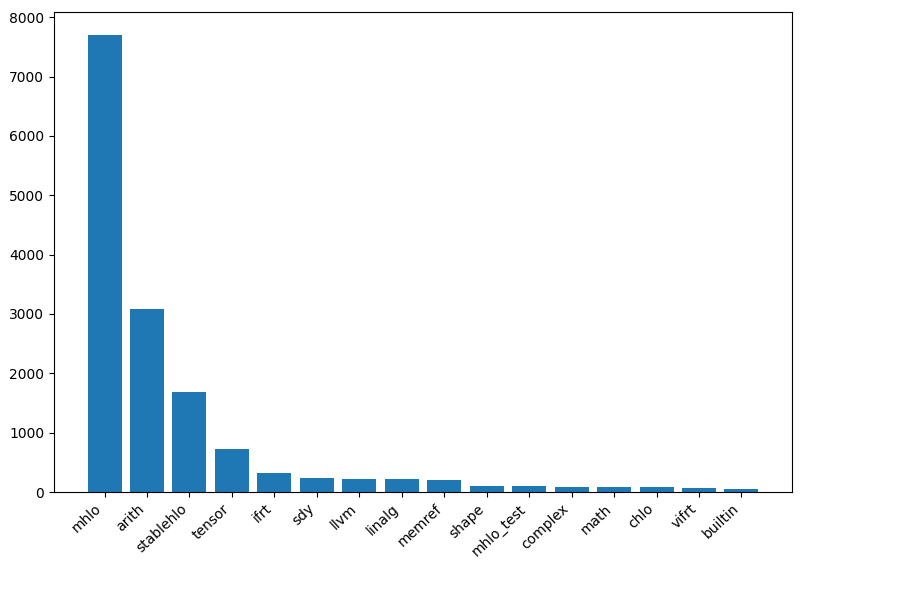
stablehlo
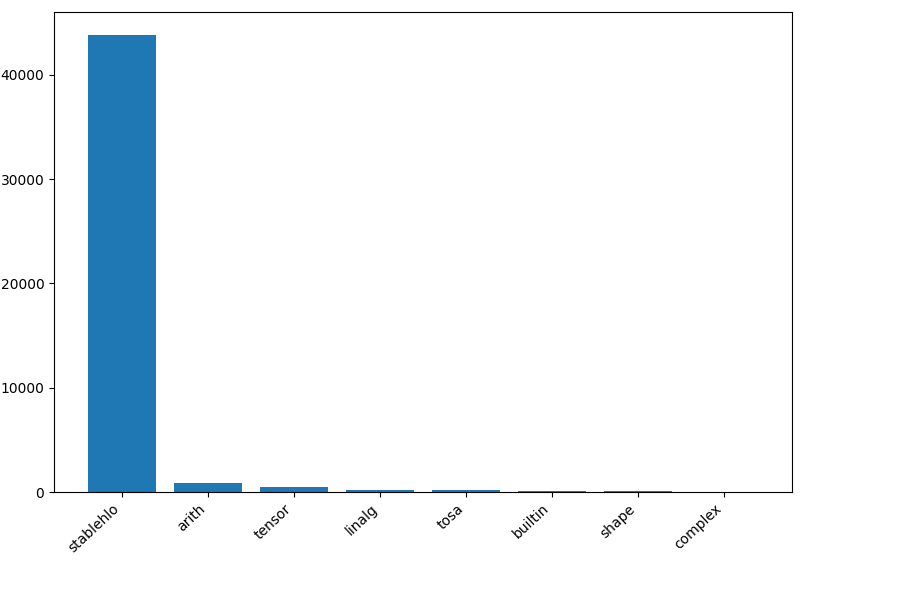
torch-mlir
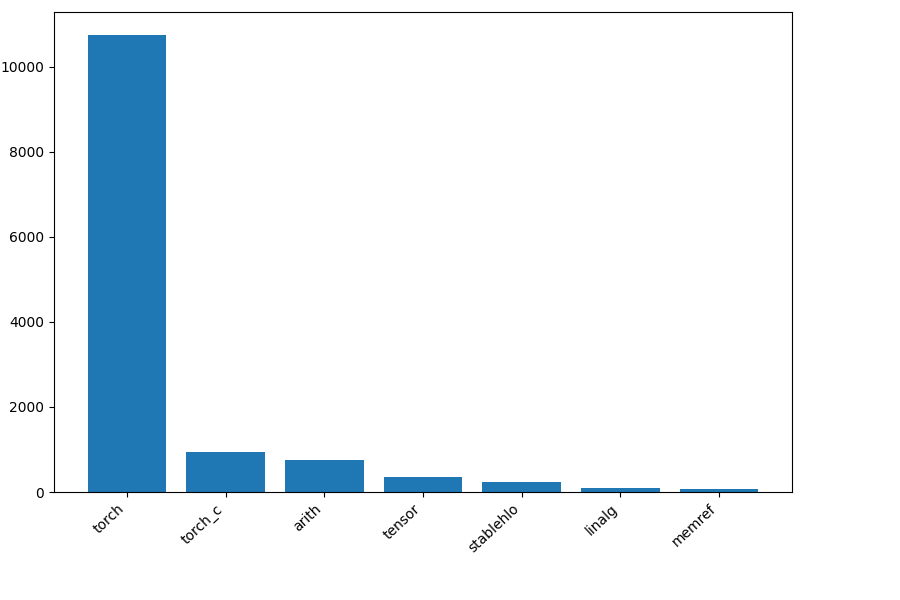
triton
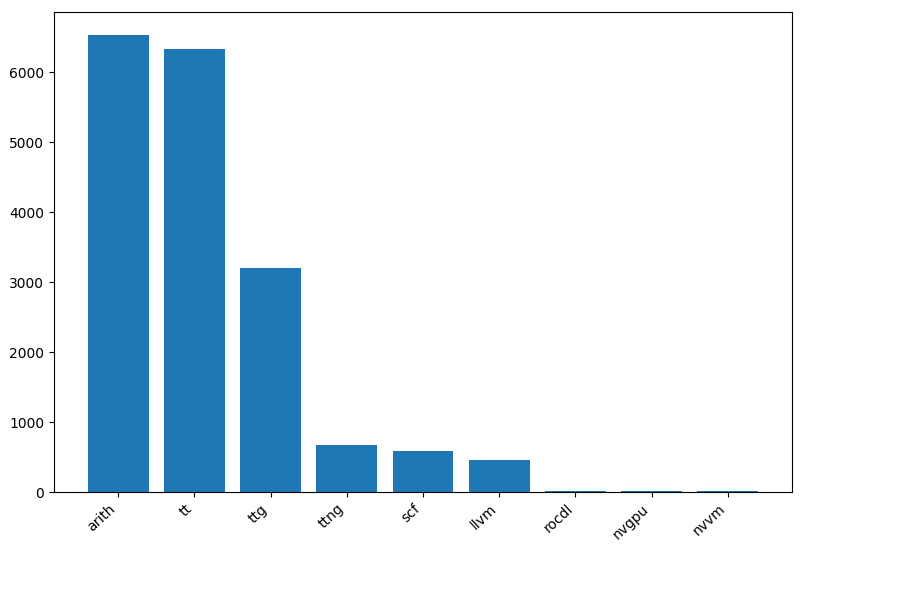
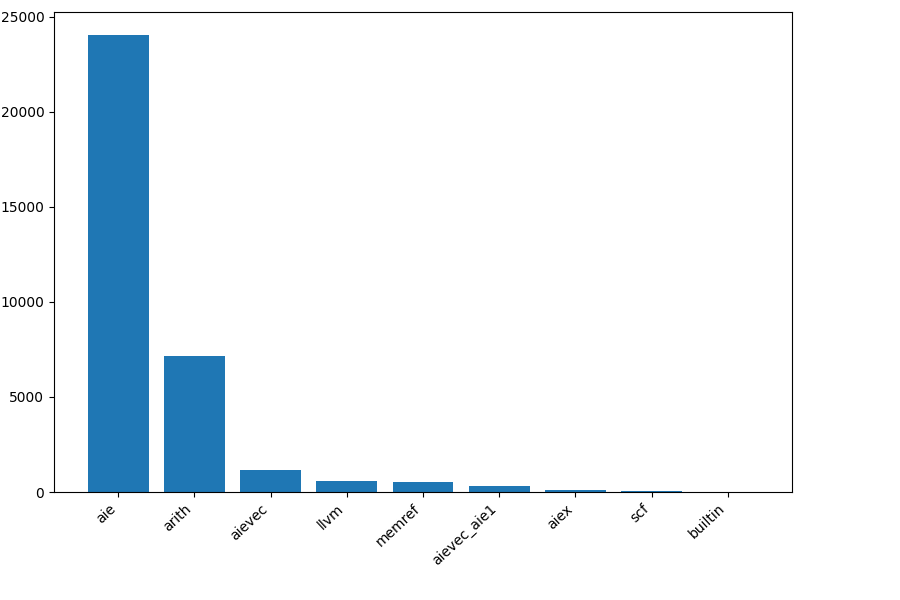
mlir-aie
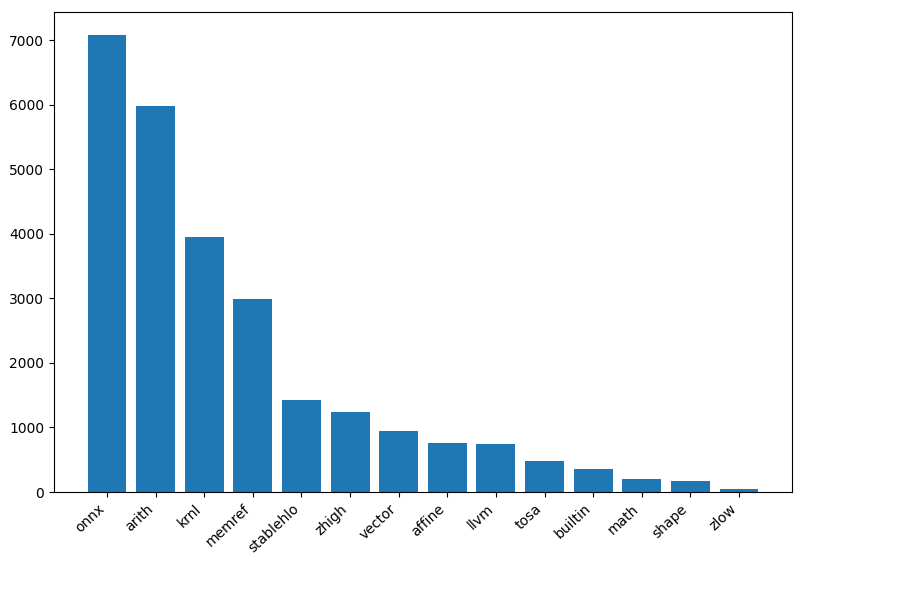
onnx-mlir
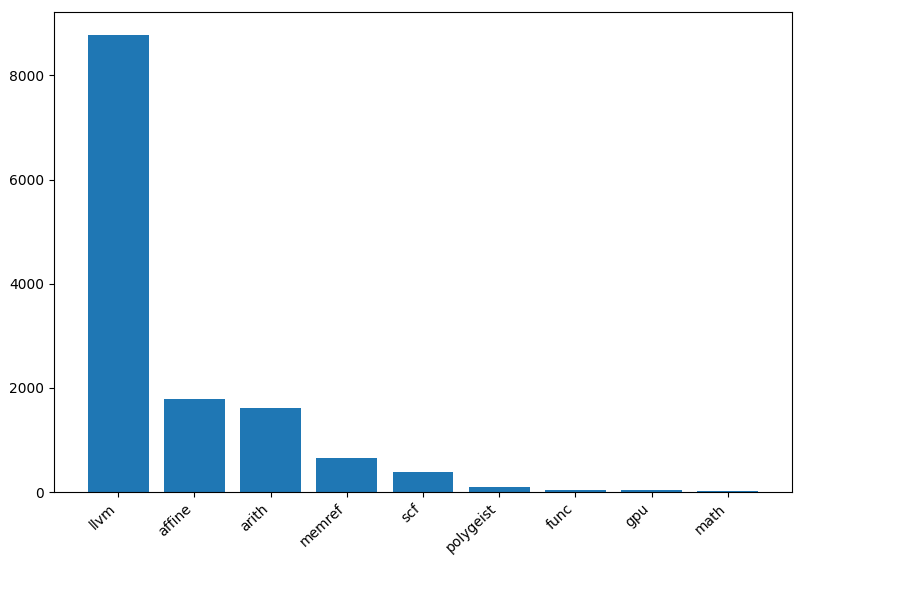
Polygeist
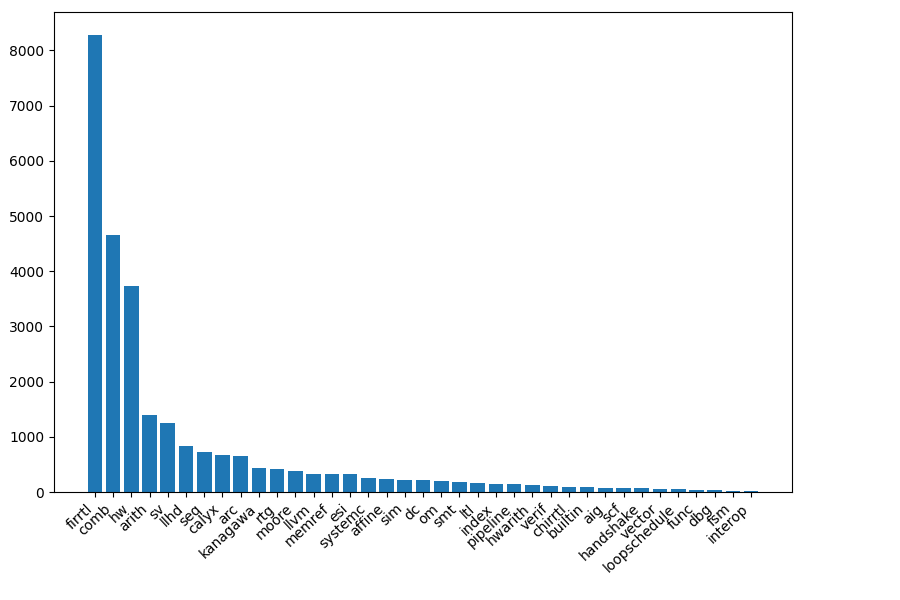
circt
Accera